

CyLab Researchers Develop Taxonomy for AI Privacy Risks
Privacy is a key principle for developing ethical AI technologies. But as technological advances in AI far outpace regulation of these technologies, the responsibility of mitigating privacy risks in goods and services that incorporate these technologies falls primarily on the developers of these goods and services themselves.
That’s a tricky proposition for AI practitioners, and it starts with tangibly defining AI-driven privacy risks in order to address them in the research and development stage of new technologies.
And while there is a privacy taxonomy that has a well-established research-driven foundation(opens in new window), it’s likely that groundbreaking AI technological advancement will bring with it unprecedented privacy risks that are unique to these new technologies.
“Practitioners need more guidance on how to protect privacy when they’re creating AI products and services,” said Sauvik Das(opens in new window), assistant professor at Carnegie Mellon University’s Human-Computer Interaction Institute (HCII)(opens in new window).
“There’s a lot of hype about what risks AI does or doesn’t pose and what it can or can’t do. But there’s not a definitive resource on how modern advances in AI change privacy risks in some meaningful way, if at all.”
In their paper, “Deepfakes, Phrenology, Surveillance, and More! A Taxonomy of AI Privacy Risks(opens in new window),” Das and a team of researchers seek to build the foundation for this definitive resource.
The research team, which also features Carnegie Mellon University researchers Hao-Ping (Hank) Lee(opens in new window), Yu-Ju (Marisa) Yang(opens in new window) and Jodi Forlizzi(opens in new window), constructed a taxonomy of AI privacy risks by analyzing 321 documented AI privacy incidents. The team’s goal was to codify how the unique capabilities and requirements of AI technologies described in those incidents generated new privacy risks, exacerbated known ones, or otherwise did not meaningfully alter known risks.
Das and his team referred to Daniel J. Solove’s 2006 paper “A Taxonomy of Privacy(opens in new window)” as a baseline taxonomy of traditional privacy risks that predate modern advances in AI. They then cross-referenced the documented AI privacy incidents to see how, and if, they fit within Solove’s taxonomy.
“If the incidents where we’re seeing the AI causing harm is challenging that taxonomy, then that’s an instance where AI has changed privacy harm in some way,” explained Das. “But if the incident fits neatly into the taxonomy, then that’s an instance where maybe it’s just exacerbated the existing harm, or maybe it hasn’t meaningfully changed that privacy harm at all.”
In examining the documented AI privacy incidents through the lens of Solove’s taxonomy, the team identified 12 high-level privacy risks that AI technologies either newly created or exacerbated, outlined in the table below.
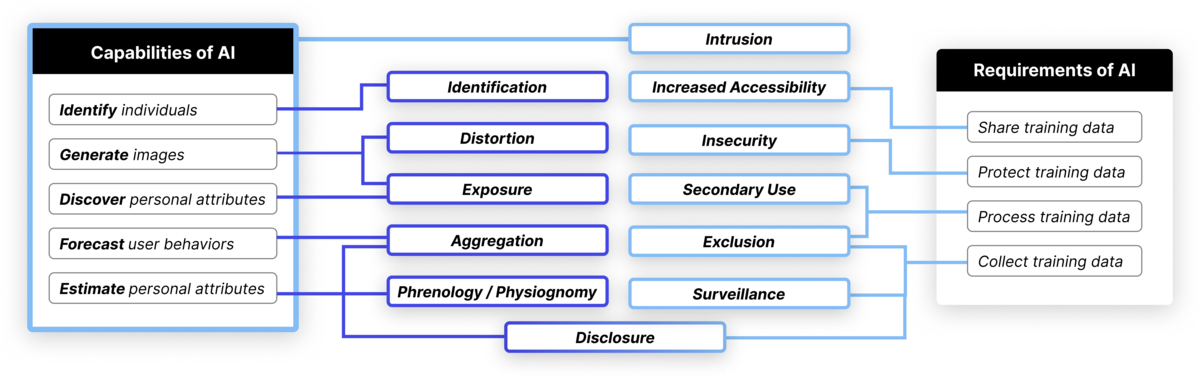
The researchers identified 12 privacy risks that the unique capabilities and/or requirements of AI can entail. For example, the capabilities of AI create new risks (purple) of identification, distortion, physiognomy and unwanted disclosure; the data requirements of AI can exacerbate risks (light blue) of surveillance, exclusion, secondary use and data breaches owing to insecurity.
“We set a divide as it relates to products and services and in two ways that pipe into the taxonomy: the requirements of AI and the capabilities of AI,” said Das.
“The requirements of AI refers to ways that the data and infrastructural requirements of AI exacerbated privacy risks already captured in Solove’s taxonomy.
“The capabilities of AI refers to its ability to do things like infer information about users to predict where they’re going to go next or what they’re going to do next.”
Two examples of newly created privacy risks resulting from AI technologies that the researchers identified are physiognomy (the long debunked pseudoscientific art of judging one’s character from facial characteristics) and the proliferation of deepfake pornography.
“There’s a ‘distortion’ category in Solove’s taxonomy which addresses instances where information about you can be used against you, which at a general class would capture this use of deepfakes,” said Das. “But there’s something fundamentally new about the capability of AI to take information about you in one context and generate it to make photorealistic content about you in another context that information and computing technology wasn’t able to do in the past in a way that wasn’t obvious, or at least not without a lot of effort. It represents a new category of distortion risks that never existed in the past, and AI has fundamentally changed that.”
Das and his team will present their findings in May at the Association for Computing Machinery(opens in new window) 2024 Computer-Human Interaction Conference(opens in new window) in Honolulu. They hope to build on their current research to make it easier for practitioners and regulators to use their taxonomy to mitigate privacy risks when developing and managing these technologies.
“Soon, we’re going to have a web version of this taxonomy, so that should make it a little bit more accessible,” said Das. “Our hope is that this taxonomy gives practitioners a clear roadmap of the types of privacy risks that AI, specifically, can entail.”